
隐私计算≠数据合规,隐私计算你知道多少呢?
当前在数据要素价值盘活过程的数据生产加工、数据资源汇聚、数据流通交易、数据模型训练与部署过程中仍然面临数据确权难、投入成本高、数据集质量低、数据资源有限等问题。各数据主体之间、甚至数据主体内部之间都因为数据安全问题而存在着数据孤岛现象,在数据流通、数据应用等方面都存在诸多问题。
综上所述∶数据时代下,政策导向明确,企业间数据流转大势所趋,个人隐私保护迫在眉睫,都将促使隐私机计算技术成为数字经济时代建设的新基建。
一、隐私计算是什么?
很难给隐私计算一个正确的定义,毕竟是个热词、大词,属于Buzz Word,还在动态发展。
只能说隐私计算是一个技术领域、或者是一系列技术集合,它要实现的目标是保证敏感数据不泄露的情况下实现计算分析。
举个例子,老王想跟老李比一下谁存款金额更多,但是双方都不想泄露各自真实的存款金额,怎么办?这个时候隐私计算就派上用场了(具体计算的细节我们后续再分享),在计算过程中,双方的真实存款金额都会被保密,而且是理论可证的。
那隐私计算是万能的吗?我们把刚才的问题改一改,老王想知道跟老李的“平均存款金额”,但是双方都不想泄露各自真实的存款,怎么办?其实这个场景本身是个伪命题,因为计算结果会倒推出双方的存款金额从而造成隐私泄露。
先抛一个观点:隐私计算离开了具体业务场景讨论就可能会有问题,不同的业务场景所依赖的数据不一样、数据处理方式不一样,背后的合规要求、安全要求也不尽相同。
二、有哪些主流的隐私计算技术?
隐私计算领域的技术还挺多,主流的技术主要有四种:安全多方计算、同态加密、可信执行环境、联邦学习四大类,像K匿名、差分隐私、脱敏等技术路线我们就不在此讨论了。
1、安全多方计算(Secure Multi-Party Computation)
安全多方计算(Secure Multi-party Computation, MPC)是一种密码学领域的隐私保护分布式计算技术。安全多方计算能够使多方在互相不知晓对方内容的情况下,参与协同计算,最终产生有价值的分析内容。
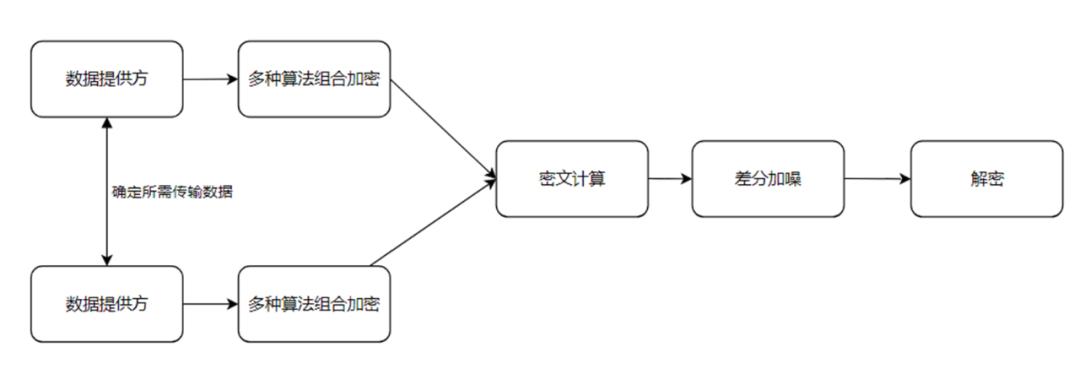
实现原理上,安全多方计算并非依赖单一的安全算法, 而是多种密码学基础工具的综合应用,包括同态加密、差分隐私、不经意传输、秘密分享等,通过各种算法的组合,让密文数据实现跨域的流动和安全计算。本文第三部分会简单介绍其中的部分算法,来阐述其具体保护原理。
下面是安全多方计算的其中一种简单实现方案示意图:
2、同态加密(Homomorphic Encryption)
同态加密简称HE,有半同态(Partial Homomorphic Encryption)和全同态(Full Homomorphic Encryption)。前者指的是能够在密文是进行加法或者乘法云上,后者是既能做加法也能做乘法。
对经过同态加密的数据进行处理得到一个输出,将这一输出进行解密,其结果与用同一方法处理原始数据得到的输出结果是一样的。
同态加密的特色是具备不错的安全共识、同时也更加通用。
想象一下,数据的计算都不是基于原始明文数据的,而是在密态数据上进行计算,计算结果也是加密的,这样就不仅保护了原始数据,而且对计算结果也进行了保护。数据的流通不再是明文数据被到处复制、到处留存、到处滥用,而是有理论基础保护的流通,数据的归属权、使用权等都将得到极大的保护。
当然现实是骨感的,同态加密的性能比明文计算约慢4个数量级,如果明文计算对应的是火箭速度,那同态加密对应的就是小孩走路速度。同态加密的普适应用,还面临着巨大的技术挑战。
3、可信执行环境(Trusted Execution Environment)
可信任执行环境(Trusted Execution Environment, TEE)指的是一个隔离的安全执行环境,在该环境内的程序和数据,能够得到比操作系统层面(OS)更高级别的安全保护。
同时计算数据通过相关密码学算法加密,来保证数据只能在可信区中进行计算,其简单实现示意图如下所示:

4、联邦学习(Federated Learning)
联邦学习简称FL,是指多个参与方在不交换“原始数据”的情况下,仅交换模型参数和中间结果,完成机器学习训练和预测。在FL中,一般会采用MPC、HE、TEE来进一步对中间计算结果数据进行保护。
FL的理念就是数据不动模型动,原始数据不出域,只有模型出域。联邦学习脱胎于分布式机器学习,所依赖的数据分布于不同的数据中心,这些数据中心可能还属于不同的法律主体。
联邦学习一般应用于联合风控、医疗图片联合建模,比如金融机构和互联网机构进行联合建模,对用户的信用进行计算,比如学术机构和各家医院对新冠肺炎的CT图进行联合深度学习训练,从而实现不逊于医生能力的AI诊断医生。
联邦学习的特色就是原始数据不出域,只有机器学习模型等中间数据会出域,所以性能上还是高效的。
当然FL的安全性跟TEE一样是无法得到理论证明的,且代码实现过程中同样会存在不少技术漏洞,从而导致数据泄露问题。
此外,由于联邦学习引入了机器学习的能力,而机器学习的安全性近几年正在被广泛研究,类似的对抗样本问题、后门攻击问题、成员推断问题等都需要被重视。
三、隐私计算≠数据合规
正如上文所述,隐私计算是一系列技术解决方案的结合体,这些技术群可以成为数据合规领域中可行的“技术解”,目前实务界普遍存在的一个误区是做好隐私计算就等于做好了数据合规。但实际情况却并非如此。
1、 隐私计算技术群本身不能解决数据来源的合法性问题。
隐私计算技术群关注的是收集完毕原始数据之后对原始数据的匿名化和有效利用,但原始数据的来源是否合法则不是隐私计算技术群能够解决的问题,不仅如此,由于隐私计算技术群中的安全多方计算和联邦学习机制会将多个不同的主体拉入数据处理的过程中,其不仅不能解决数据来源的合法性,反而会在一定程度上增加由于某个数据的来源不合法而造成全体数据处理者共同侵权的风险。
此处以个人信息为例,我国《个人信息保护法》第十三条明确指出,个人信息处理者应当在取得个人同意的前提下处理个人信息,倘若个人信息处理者所处理的个人信息来源存在问题(如未经同意收集个人信息),则再如何进行隐私计算也于事无补。在实务中,由于隐私计算技术群的特性,通常会有多个主体共同参与个人信息数据的隐私计算,共同成为个人信息处理者,当其中一个主体获得个人信息未得到授权,其他所有主体均会被“污染”,成为共同侵权者,因此,倘若数据来源的合法性无法保证,隐私计算不仅不能起到合规目的,反而还会增加侵权风险。
2、 经过隐私计算处理后的数据,不一定完全符合“匿名化”要求
隐私计算技术群实现数据匿名化的程度差异极大,经过隐私计算技术群处理过的数据在很大程度上可以进行逆向工程,因此就数据合规角度而言,隐私计算不是一个“有或无”的问题,而是一个“程度大和程度小”的问题,即使某一主体做到了数据源合法,也有隐私计算机制,依然无法得出有效做到数据合规这一结论。
以联邦学习技术为例,在终端使用联邦学习对用户行为进行建模时,参与方需要在终端手机用户的出行、消费等数据,并将模型的梯度信息进行交换。由于对梯度数据进行逆向工程的难度较小,很容易被还原成原始数据,因此梯度数据仍然属于《个人信息保护法》第四条所规定的个人信息,而非“匿名化处理后的信息”。倘若未经用户同意泄露这些梯度信息,便构成侵权。
综上所述,以安全多方计算、联邦学习、可信执行环境、同态加密等技术为代表的隐私计算技术群无法保证数据来源的合法性,对于是否能够保证数据的匿名化,还需要根据实际情况进行评估。简言之,隐私计算技术群无法绝对豁免数据合规要求,隐私计算不等于数据合规,数据处理主体是否有效做到数据合规,应当结合具体应用场景、技术方案、数据授权内容等综合判断合规风险点位。
总结
隐私计算是一个正在发展的领域,技术还不够成熟,应用还不够广泛,但是前景还是美好的。
数据合规是一个很大的领域,隐私计算是一种能够实现最小化处理合规义务的技术之一,更不等于数据合规,也无法实现匿名化。该做的合规义务,无论是数据来源合法、还是影响评估、还是单独同意等,该有的一个都不能少。隐私计算对数据保护的强度是很高的,也正是这样的技术特色实现了最小化处理的合规义务,但这不代表可以偷偷绕过各种合规义务。

